Spodbuda za blog je nastala v okviru seminarja ADP Načrtovanje ravnanja s kvalitativnimi raziskovalnimi podatki: primer Spomin na medije v Jugoslaviji, ki je potekal 7. septembra 2021. Gosta seminarja sta bila dr. Jernej Amon Prodnik in dr. Jernej Kaluža iz Centra za raziskovanje družbenega komuniciranja na Fakulteti za družbene vede, ki sta se sprehodila skozi življenjski krog podatkov in predstavila nekaj dilem in rešitev, ki vodijo do kakovostne podatkovne objave. Med drugim predstavita tudi konkretne postopke, ki jih je potrebno izvesti pred arhiviranjem podatkov in njihovo znanstveno rabo.
Posnetek seminarja si oglejte na Youtube kanalu ADP. Prezentacije so dostopne na spletni strani ADP: prvi del in drugi del.
Podatki iz raziskave, ki jo predstavljata, so dostopni v Katalogu ADP.
________________________________
Piše: dr. Jernej Kaluža
V pričujočem prispevku bomo predstavili nekaj napotkov pri analizi obsežnejših zbirk kvalitativnih podatkov, denimo intervjujev. Izhajali bomo iz raziskave Novinarstvo v socialistični Jugoslaviji in imaginariji medijev skozi občinstvo, ki poteka od leta 2019, in v okviru katere bo v kratkem arhiviranih 96 intervjujev, ki so jih opravili študentje in študentke s svojimi starimi starši ali drugimi starejšimi osebami. Ti intervjuji se tematsko osredotočajo na uporabo medijev v času socialistične Jugoslavije. Poleg tega je v njih pogosto predstavljeno tudi širše razumevanje ter vrednotenje socialističnega režima in še posebej novinarstva ter medijev času Jugoslavije.
V svojem prispevku za blog ADP je dr. Jernej Amon Prodnik že predstavil vidik dela s študenti in etične dileme, ki se v tem kontekstu pojavljajo. Te tematike bom tokrat (tudi zato, ker v delo s študenti nisem bil posebej globoko vpleten) pustil ob strani. Osredotočil se bom na predstavitev nadaljnjega dela, ki smo ga v okviru omenjene raziskave opravili od trenutka, ko so študentje že oddali transkripte opravljenih intervjujev. Ta besedila je bilo potrebno obdelati in sistematično urediti z namenom njihovega arhiviranja v ADP. Obenem pa smo ta besedila tudi kvalitativno analizirali in jih »kodirali« glede na obravnavano vsebino. Ti postopki niso posebej specifični za našo raziskavo in jih je mogoče nasploh razumeti kot generične v primeru raziskav, ki temeljijo na večji količini besedilnih podatkov.
Slogovno in oblikovno urejanje transkriptov
Osnovni napotki glede transkribiranja na spletni strani ADP (glej Vodič za pripravo transkriptov v družboslovju) že obstajajo. Intervjuje lahko transkribirajo izvajalci intervjujev, raziskovalci, profesionalne službe, za nekatere svetovne jezike pa deluje tudi avtomatska transkripcija, ki pa v primeru slovenščina – vsaj po moji vednosti – še ne da zadovoljivih rezultatov. V praksi je pri transkriptih pomembno da so med seboj, še posebej če jih opravljajo različne osebe, čim bolj slogovno in oblikovno poenoteni. To pomeni, da morajo biti v vseh intervjujih enak način ločevanja med vprašanji in odgovori, enaka pisava, razmak vrstic, ipd. V ta namen so v primeru naše raziskave študentje dobili osnovne napotke glede transkribiranja in vzorec transkripta, ki so mu morali slediti. Smiselno je tudi, da so na začetku vsakega transkripta navedeni osnovni demografski podatki o intervjuvancu (ime, spol, starost, itd.) in osnovni podatki o samem intervjuju (čas, kraj, trajanje itd.). Z vidika kvalitete in raznovrstnosti rabe raziskovalnih podatkov je gotovo koristno, če transkript čim natančneje posnema govor, vključno z rabo narečja in vključenimi opisi nebesednega komuniciranja. Tovrstna natančnost sicer lahko predstavlja v določenih situacijah tudi problem (različni zapisi iste besede, denimo »televizija« in »televizja« delajo težave pri iskanju po ključnih besedah ali pri avtomatski obdelavi podatkov). Zato smo študentom v navodilih svetovali, naj ne posnemajo na silo pogovornega jezika (vendar naj vseeno upoštevajo osnovne značilnosti govorjenje besede). Poleg tega smo jim svetovali uporabo oglatih oklepajev za razlago nebesednega komuniciranja, velikih črk (za glasen govor) in podčrtovanja (za poudarjeno intonacijo). V znanstvenem kontekstu je namreč splošno načelo transkribiranja, da to ohrani čim več podatkov izvornega govora in tega posnema, kar pa lahko v praksi predstavlja tudi problem, posebej v kolikor se intervjuje daje v avtorizacijo, saj nekateri pričakujejo, da bodo transkripti prečiščeni na podoben način kot so pri objavljenih intervjujih v medijih.
Anonimizacija: kvaliteta podatkov in varovanje zasebnosti
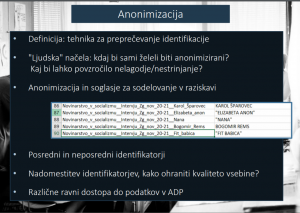
Eden izmed najpogostejših korakov pri obdelovanju podatkov za namene njihovega arhiviranja je anonimizacija, katere namen je preprečevanje identifikacije. O tem postopku je na spletni strani ADP mogoče najti kar nekaj koristnih informacij (glej npr.
Orodje za anonimizacijo QualiAnon in Priročnik: Anonymisation Decision-Making Framework book). V primeru polstrukturiranih spominskih intervjujev je vredno temu procesu posvetiti še posebno pozornost. Vprašanje anonimizacije je dobro imeti v mislih že preden se začne opravljati intervjuje ter ga nasloviti že v soglasju za sodelovanje pri raziskavi. V soglasju je potrebno natančno opredeliti ali (in v kolikšni meri) bo intervju anonimiziran oziroma ponuditi posamezniku izbiro, ali želi v raziskavi sodelovati anonimno ali ne. Poleg anonimiziacije intervjuvancev pa je potrebno poskrbeti tudi za anonimizacijo tretjih oseb, ki so v intervjujih omenjene, posebej če ne gre za javne osebe, funkcionarje, ipd. Poleg neposrednih identifikatorjev namreč poznamo tudi posredne identifikatorje, ki so v spominskih intervjujih posebej pogosti, saj v njih prihaja do vključevanja osebnih anekdot, ki so polne navajanja točnih lokacij, imen tovarn, šol ali dogodkov. V praksi je zato včasih težko presoditi, kdaj anonimizacija zmanjšuje kvaliteto podatkov (in kako se temu učinku izogniti). Pri anonimizaciji je smiselno slediti tudi občutku, kateri podatki bi lahko povzročili nelagodje in nestrinjanje (in ali so ti podatki relevantni za samo raziskavo). V našem primeru smo se ponekod odločili, da namesto identifikatorjev uporabili opise, ki še vedno omogočajo razumevanje konteksta povedanega (denimo »hčera sogovornika« namesto »naša Jasna«). Anonimizirali smo lastna imena (otrok, lokacij, prijateljev), ne pa krajevnih imen, imen regij, mest, ipd.
Kodiranje intervjujev in uporaba temu namenjene programske opreme
O rabi programov za analizo besedilnih podatkov na spletni strani ADP že obstajajo bolj podrobni zapisi (glej npr. prispevek z naslovom Politična participacija mladostnikov v Sloveniji, na ADP-jevem YouTube kanalu pa si je mogoče ogledati tudi seminar na to temo z naslovom Praktični vidiki rabe programov za analizo besedilnih podatkov, ki ga je vodil dr. Urban Boljka). V kontekstu naše raziskave smo strukturo vsebinskega kodiranja zasnovali tako, da je sledila vsebinskim navodilom, ki smo jih posredovali študentom. Ti so se morali osredotočati na tri glavne teme (uporaba medijev, zaupanje v medije, mnenje o režimu) skozi štiri časovna obdobja (otroštvo, mladost, srednja leta, zrela leta).
Izhajajoč iz prejšnjih izkušenj, sem se v primeru omenjene raziskave odločil, da skušam opraviti vse delo, ki terja branje zbranih podatkov – pregledovanje demografskih podatkov intervjuvancev, anonimiziranje, slogovno in oblikovno urejanje transkriptov in vsebinsko kodiranje – v enem koraku. Lahko si namreč predstavljate, da je podrobno branje transkriptov 96 intervjujev (s povprečno dolžino ene ure, kar znese cca. 6000 besed transkripta/intervju, vse skupaj pa torej cca. 576 000 besed) precej dolgotrajno opravilo. To opravilo pa bi bilo še veliko daljše, če bi najprej vsa besedila prebral z namenom priprave na arhiviranje (anonimizacija, oblikovanje besedila), ter potem še enkrat z namenom vsebinske analize (kodiranje intervjujev). Nekateri programi za analizo kvalitativnih podatkov (sam sem uporabljal NVivo 10) tudi omogočajo funkcijo urejanja in vsebinskega spreminjanja besedil. Tovrstno večopravilnostno branje sicer zahteva precej koncentracije. Prav tako priporočam predhodno branje izbranega vzorca besedil. Samo na tej podlagi je mogoč temeljit razmislek glede metodoloških postopkov in vzpostavitev sheme kodiranja (ki lahko pokrije vse v besedilih obravnavane teme), vzpostavitev kriterijev anonimizacije, seznanitev z najpogostejšimi oblikovanimi napakami, vzpostavitev jasnih vsebinskih kategorij, sistematizacija razvrščanja delov besedila, itd.
Predaja podatkov arhivu ADP

Splošne napotke glede urejanja podatkov in navodila za postopek predaje ter merila za sprejem je mogoče najti na spletni strani ADP (glej: Postopek predaje). V primeru naše raziskave smo v ADP oddali: 1.) transkripte pregledanih intervjujev, 2.) izjavo o izročitvi, 3.) obrazec opis raziskave in spremljevalno dokumentacijo (matrico, excel tabelo vseh intervjujev z osnovnimi demografskimi podatki, navodila – demografski podatki transkripta, formo transkripta in vzorec soglasja). Spremljevalni material je posebej pomemben zato, ker lahko ostalim, ki bi želeli uporabljati te podatke, razloži kontekst raziskave. Kakovostne raziskave, ki so objavljene v arhivu, se po merilih ARRS štejejo kot znanstvene objave in sicer kot »zaključena znanstvena zbirka podatkov ali korpus«, kar se vrednoti s 30 točkami. Tovrstna zbirka podatkov pridobi tudi bibliografski zapis in DOI številko, kar je smiselno navajati pri sklicevanju na bazo podatkov v člankih, s čimer se poskrbi tudi za lažjo preverljivost in reproduktibilnost raziskave. V znanstvenih revijah postaja namreč vse bolj standard, da se zahteva (ali vsaj priporoča), da so podatki, na katere se objavljeni članki sklicujejo, javno dostopni.