Od 21. do 23. junija 2017 je na Fakulteti za elektrotehniko potekal 5. ReLDI seminar o empiričnih podatkih v jezikoslovju, ki se ga je udeležilo 50 udeležencev iz petih držav nekdanje Jugoslavije. Udeležila sem se ga tudi Ana Slavec (ADP), ki sem želela poglobiti svoje znanje o jezikoslovnih podatkih, saj so korpusi spletne slovenščine (JANES) ena izmed študij primera, ki jih obravnavamo v šesti delovni skupini v okviru projekta SERISS (Obzorje 2020).
ReLDI (Regional Linguistic Data Initiative) je dvoletno institucionalno partnerstvo med raziskovalnimi organizacijami na področju jezikoslovnih poodatkov v Švici, Srbiji in na Hrvaškem, ki ga financira Švicarska nacionalna znanstvena fundacija v okviru programa SCOPES. Spletna stran ReLDI je repozitorij za vire in orodja za analizo jezikoslovnih podatkov in instrumente za zbiranje podatkov, v prihodnosti pa bo gostila tudi spletne tečaje na temo eksperimentalnih in korpusnih metod, programiranja in statistike v jezikoslovnem raziskovanju.
To so bile tudi teme, ki smo jih obravnavali na seminarju v Ljubljani, ki sta ga vodili Tanja Samardžić in Maja Miličević. Seminar je potekal v angleškem jeziku, vendar so bile prosojnice in materiali v srbskem jeziku (vsi so dostopni na spletni strani seminarja). Prvi dan dopoldne smo poslušali predavanji o podatkih in napovedovanju v jezikoslovju ter o korpusno zasnovanih jezikoslovnih raziskavah. Tako kot v drugih vedah, se tudi v jezikoslovju lahko na podlagi empiričnih podatkov napoveduje dogodke, na primer slovnične lastnosti ali obstoj določenega elementa v besedilu. Pri tem so empirični podatki najpogosteje besedilni korpusi.
Besedilni korpusi so obsežne zbirke realnih besedil v elektronski obliki, ki so zajeta iz različnih virov na način, da predstavljajo vzorec jezikovne rabe določene vrste. (Vir: Jezikovna Slovenija)

V popoldanskem delu pa smo se na vajah učili pridobivanja korpusnih podatkov preko poizvedb in jezika CQL (corpus query language) v programu SketchEngine oz. v njegovi brezplačni omejeni različici NoSketchEngine. Na koncu smo se razdelili v skupine in dobili navodila za praktično delo. Sama sem na primer sodelovala v skupini, kjer smo morale udeleženke zasnovati raziskavo, ki bi proučevala zamenljivost veznikov DA in KER v vzročnem razmerju pri glagolskih zvezah, ki izražajo pozitivno ali negativno čustvovanje/občutenje.
Drugi dan smo poslušali predavanji o vlogi eksperimentiranja v jezikoslovju, ki je pomembno, saj omogoča raziskovanje širšega nabora jezikoslovnih pojavov, višjo stopnjo kontrole nad raziskavo ter ugotavljanje vzročno-posledičnih odnosov. V popoldanskem delu pa smo se učili o pripravi podatkov za statistično analizo v programu R ter nadaljevali s skupinskim delom. Postavili smo hipotezo, izbrali metodo ter pripravili raziskovalni načrt. V moji skupini smo se odločile za korpusno metodo in podatke pridobile iz korpusa KRES.
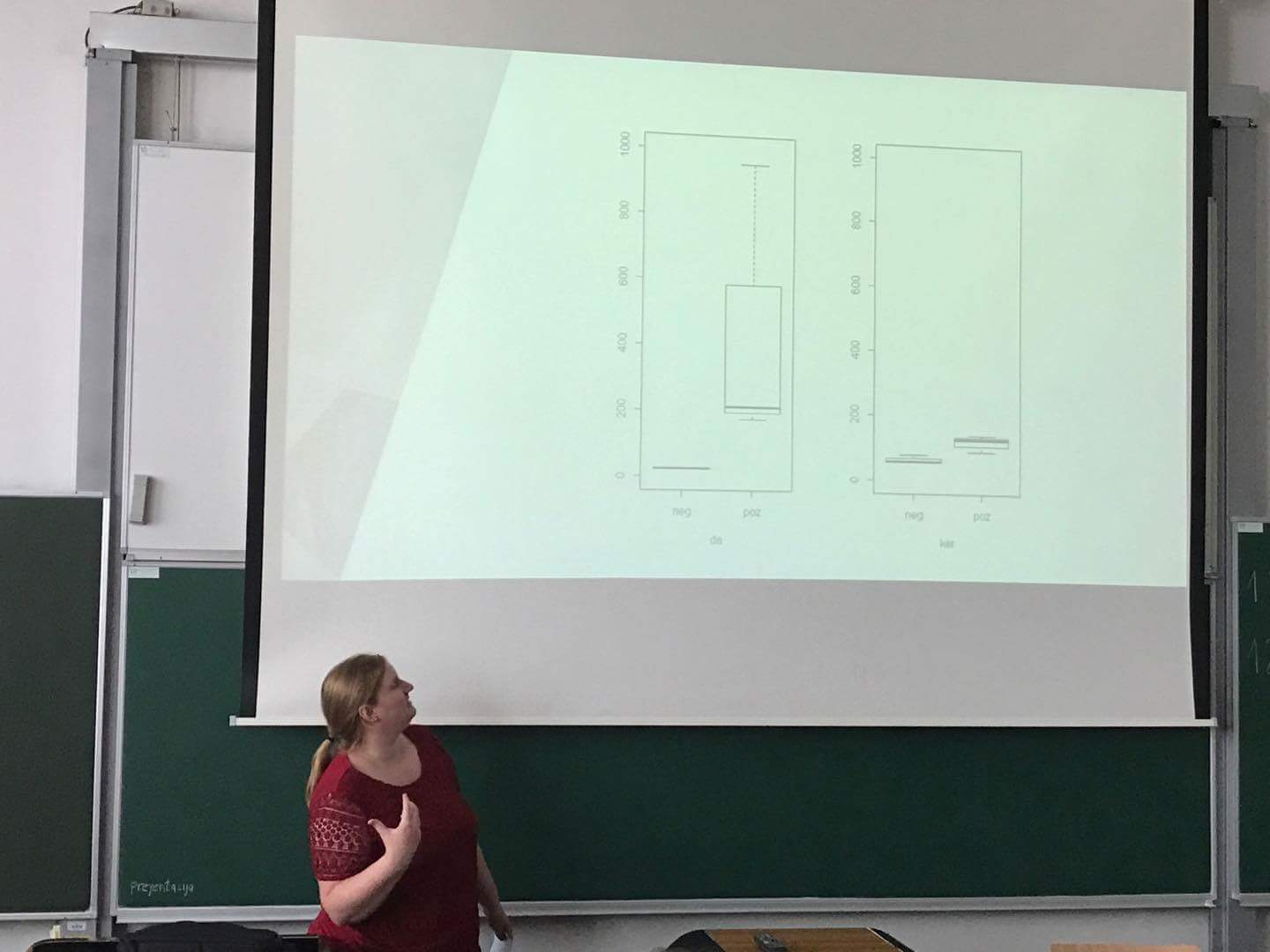
Zadnji dan smo poslušali predavanji o opisni statistiki, statistični inferenci in statističnih testih ter o analizi in vizualizaciji podatkov v R, v popoldanskem delu pa smo nadaljevali s praktičnim delom. Tabelo podatkov, ki je nastala na podlagi CQL poizvedb na korpusu KRES preko orodja NoSketchEngine, smo uvozile v R in podatke prikazale v obliki grafikona kvantilov (boxplot). Na koncu je vsaka skupina predstavila rezultate tega dela.
Seminar je bil namenjen predvsem raziskovalcem na področju jezikoslovja, ki imajo manko znanja s področja metodologije in raziskovanja in uporabe statistike. Večina udeležencev je prvič delala empirično raziskavo in uporabljala program R, zato smo začeli pri osnovah. Kot družboslovni metodologinji in statističarki so mi bile te vsebine že precej dobro poznane, zato je bilo zame dodana vrednost seminarja povsem drugje – v spoznavanju korpusne metodologije in v uvidu, kako se statistika uporablja na področju jezikoslovja. Predvsem sem poglobila znanje uporabe CQL v Sketch Engine, ki sem ga že uporabljala, vendar doslej le za osnovne poizvedbe.
Interdisciplinarnost je v sodobni znanosti izjemno pomembna, saj določenih problemov ni možno reševati le v okviru ene same discipline. Zato upam, da bo v prihodnosti še več tovrstnih dogodkov, ki omogočajo interdisciplinarno izobraževanje in povezovanje znanstvenikov.